
Meta AI推出 Meta MovieGen AI 视频生成模型,用于创建沉浸式视频和音频内容。它是媒体生成领域的突破,支持用户通过简单的文本描述生成独特的定制化视频,并进行复杂的视频编辑,甚至可以将个人照片转化为动画视频。
MovieGen 模型的核心是一种多模态生成架构,它抛弃了触痛的扩散模型架构,是基于 Transformer 模型的多媒体生成模型,用于生成高质量的图像、视频和音频。这意味着它不仅处理单一的数据形式(如图像或文本),而是同时处理文本、图像和声音等多种输入。多模态生成架构的优势在于能够整合不同类型的输入数据,并生成具有一致性的多媒体输出。


它主要包括两个基础模型:Movie Gen Video 和 Movie Gen Audio,分别负责视频和音频的生成。
- 30B参数的Movie Gen Video模型:Movie Gen Video是一个大型文本到视频生成模型,具有30B的参数,能生成高质量的16秒高清影像(16帧/秒),支持多种分辨率和视频长度。
- 音频生成模型Movie Gen Audio:13B参数的音频生成模型,能够生成48kHz的高质量音效和背景音乐,并与视频同步。
- 跨模态生成:MovieGen 可以从文字生成视频,并同时生成与视频匹配的音效或背景音乐。通过这项技术,系统能够自动生成完整的视频作品,减少了人工制作的步骤。
- 高精度模型:MovieGen 的 AI 模型经过了海量数据的训练,具备理解复杂场景和生成高保真视频内容的能力。这使得生成的视频不仅具备视觉上的美感,还能够准确反映文本中的细节,如光影效果、人物动作等。
- 个性化与可定制性:用户可以通过输入自己的图片或视频,并根据文本进行进一步的修改与定制,生成个性化的高质量视频内容。
- Movie Gen在多个生成任务上超过了当前的商用系统,包括Runway Gen3、LumaLabs、OpenAI Sora等,尤其是在视频个性化生成和精确视频编辑上显示出明显优势。
- 在音频生成方面,Movie Gen Audio模型在声音效果生成、音乐生成和音频扩展任务上也超越了ElevenLabs和PikaLabs等现有的商用系统。
核心功能详解
文本生成视频: MovieGen 的核心功能之一是从文本生成高质量的视频。利用一个30B参数的Transformer模型,从文本提示生成高质量、高清晰度的图像和视频,支持最长16秒、16帧/秒的视频生成。用户只需输入一个简短的描述,例如“一个女孩在沙滩上奔跑并放风筝”,MovieGen 会基于这个文本输入自动生成相应的视频。
其突破性特点在于:
- 多样性:支持不同纵横比的视频生成,可以生成从短片到长视频的各种内容形式。
- 高分辨率:MovieGen 生成的视频具有高清质量,适用于不同的展示需求。
- 创意多样性:通过简单的文字描述,用户可以生成具有高度定制化、创意十足的内容。比如,一个“带着粉色太阳镜的树懒漂浮在泳池里的甜甜圈浮床上”这样的描述就能生成一个生动的动画场景。
视频编辑功能: MovieGen 不仅能生成新视频,还可以通过文本编辑现有视频。这项功能使得用户可以用文字直接控制视频中的具体变化。根据文本提示精确修改视频,允许局部编辑和全局变化(如背景或风格修改)。
比如:
- 精细化编辑:用户可以修改视频的风格、过渡效果,甚至是一些细微的画面细节。这使得视频编辑变得更加便捷和直观,无需专业的视频剪辑技能。
- 场景和物体的编辑:通过输入文字,用户可以替换或修改视频中的场景和物体。例如,用户可以在视频中替换背景,改变视频的色调或修改某个角色的动作。
个性化视频生成: MovieGen 支持将用户上传的个人照片或图像转换为动态视频。这一功能基于 Meta AI 的先进图像识别和生成模型,可以生成逼真且具有一致性的人物动作,保持人物身份特征。这意味着用户可以轻松地将静态照片转换为动态视频,例如制作个性化的头像视频,或者将个人肖像融入创意视频中。这对社交媒体、个性化广告以及创意内容创作具有巨大的应用潜力。
音效与背景音乐生成: MovieGen 除了生成视频,还可以生成音效和背景音乐,进一步丰富了用户创作的可能性。通过文本输入,用户可以生成相应的音效,例如“雨水拍打悬崖”的声音,或为视频定制背景音乐,如“激发奇迹感的管弦乐”。此功能让用户能够无缝地为视频添加音效和配乐,从而提升视频的沉浸感和表现力。
模型架构及技术创新
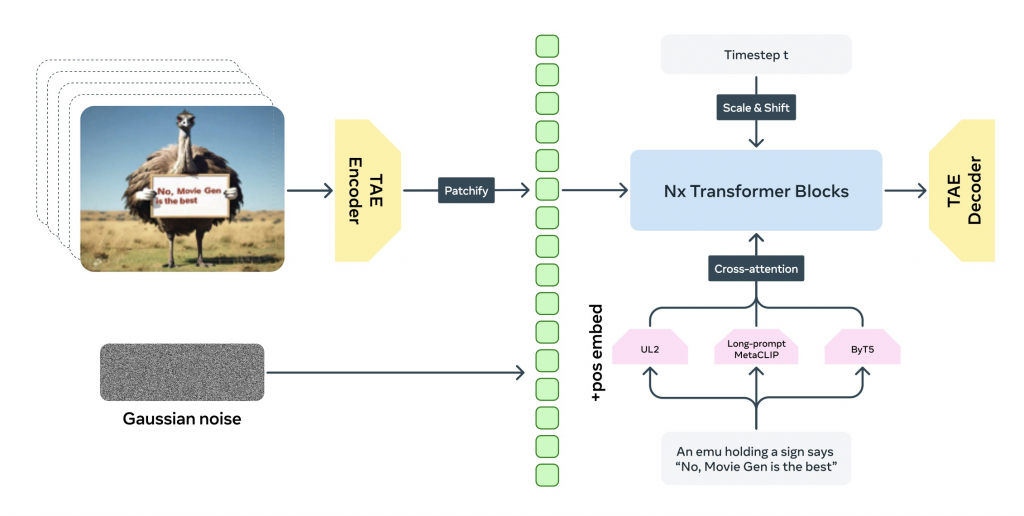
Meta MovieGen 是一个先进的多模态生成模型,结合了文本、图像和音频数据,通过深度学习技术生成视频和音效。其架构基于生成对抗网络(GAN)、变分自编码器(VAE)以及多模态融合技术,能够在生成逼真的视频内容的同时,结合相应的音效和背景音乐。以下是该模型的架构详解:
1. 多模态生成架构
MovieGen 模型的核心是一种多模态生成架构,这意味着它不仅处理单一的数据形式(如图像或文本),而是同时处理文本、图像和声音等多种输入。多模态生成架构的优势在于能够整合不同类型的输入数据,并生成具有一致性的多媒体输出。其多模态架构分为以下几个主要部分:
- 文本编码器:负责将用户输入的文本描述编码为向量表示。MovieGen 使用先进的自然语言处理(NLP)技术,如 Transformer 或 BERT,将自然语言转换为适合生成任务的语义表示。这种编码器能够捕捉文本中的细微语义,确保生成的视频与用户输入的文本高度一致。
- 图像编码器和解码器:用于处理用户输入的图像(如个性化视频生成中的照片),并将其编码为特征向量。图像编码器使用卷积神经网络(CNN),通过多层卷积和池化操作提取图像的关键特征。解码器则反向生成视频帧,确保生成的视频帧保持一致性和流畅性。
- 音频生成模块:MovieGen 通过结合文本描述和视频内容生成音频。其音频生成模块使用波形生成模型(如 WaveNet)或基于频谱分析的技术,确保生成的音效与视频场景匹配。例如,文本描述中的”雨声”将被转换为逼真的音效,并与视频同步生成。
- 多模态融合模块:该模块负责整合来自不同模态(文本、图像和音频)的信息。通过联合训练多模态网络,MovieGen 能够在不同数据类型之间建立一致的语义联系,从而确保生成的视频内容与音效和文本描述完全匹配。
2. 生成对抗网络(GANs)
MovieGen 的视频生成部分采用了生成对抗网络(GANs),这一技术在图像和视频生成领域具有强大的表现力。GAN 的架构由两个网络组成:
- 生成器(Generator):负责根据输入的文本和图像特征生成视频帧。生成器通过将文本和图像特征输入到一个卷积神经网络中,逐帧生成符合描述的高质量视频。
- 判别器(Discriminator):用于判定生成的视频帧是否逼真,以及是否与输入的文本描述匹配。判别器不断与生成器进行博弈,促使生成器生成更真实、更符合文本描述的高质量视频内容。
MovieGen 的 GAN 架构经过大量数据训练,可以生成具有高度视觉逼真的视频,且能够保持视频帧之间的连续性,解决了传统视频生成中常见的“帧间不连贯”问题。
3. 变分自编码器(VAE)
除了 GAN,MovieGen 还结合了变分自编码器(VAE)技术,特别是在个性化视频生成和音效生成方面。VAE 的主要作用是处理视频中复杂的非确定性场景,比如随机生成的动态场景或音效。
- VAE 的编码器:将输入的数据压缩为一个潜在的低维空间表示,这些表示通常包含了视频或音效中的关键信息。
- VAE 的解码器:将潜在空间中的信息解码为全分辨率的音频或视频内容。通过这种方式,MovieGen 可以生成具有多样性和随机性的场景和音效。
4. Transformer 模型
MovieGen 采用了 Transformer 结构进行长视频的生成。Transformer 模型在处理长距离依赖(如视频的时序一致性)时具有显著优势。其优势在于:
- 自注意力机制:Transformer 通过自注意力机制,能够捕捉视频帧之间的长距离依赖关系,确保视频在生成时序一致的帧序列时,不会丢失先前帧中的重要信息。
- 时序建模:为了确保生成的视频具有流畅的时间轴,MovieGen 使用了改进的时序 Transformer 模型,能够有效处理视频帧之间的连续性问题。这使得生成的长视频不仅视觉一致,且动作和场景变化流畅自然。
5. 个性化生成网络
MovieGen 的个性化生成功能基于人脸识别和姿态估计模型。用户上传的照片会通过人脸识别算法提取关键特征点,如面部轮廓、眼睛、鼻子和嘴巴等,然后通过姿态估计网络生成个性化的动画。这种生成网络具有如下特点:
- 身份保持:模型能够保持用户的面部特征和整体身份一致性,确保生成的个性化视频能够真实反映用户的外貌。
- 动态生成:通过结合姿态估计,模型能够生成包含动作的动态视频。例如,将静态头像转化为跳舞或跑步的动画。
6. 音效生成与同步
MovieGen 的音效生成基于对音频和视频同步的严格要求。通过多模态联合训练,MovieGen 可以确保生成的音效与视频动作完全匹配。其音效生成模块包含以下技术:
- WaveNet:一种基于生成模型的音频生成框架,能够生成逼真的声音和背景音乐。
- 频谱分析:通过对文本描述的语义分析,模型可以生成与视频场景相匹配的频谱,并利用这些频谱生成音效。
7. 训练与优化
MovieGen 模型的训练涉及大量的跨模态数据,包括视频、文本和音频。通过大规模的数据集训练,模型学会了在不同模态之间建立准确的映射关系,并优化生成质量。其训练过程使用了以下技术:
- 大规模预训练:模型使用了大量的视频和文本对进行预训练,确保其能够生成符合现实场景的视频。
- 精调(Fine-tuning):在不同应用场景下,MovieGen 可以通过精调适应特定任务,如广告视频生成、电影场景生成等。
Movie Gen 的技术创新包括:
- 时空自编码器(TAE):将视频压缩到时空潜在空间,减少计算负担,生成高分辨率长时段视频,确保时间一致性。
- 流匹配(Flow Matching)训练目标:相较传统扩散模型,流匹配在视频生成中更鲁棒,提高了生成效果和效率。
- 联合图像与视频生成:统一模型生成图像和视频,提升模型泛化能力,支持多分辨率和多时长视频生成。
- 个性化视频与精确编辑:通过后训练支持个性化视频生成,精确编辑视频元素,简单高效,现有商用系统中尚无此功能。
- 高效空间上采样器:将低分辨率视频放大到1080p高清,降低生成高分辨率视频的计算成本。
- 多重并行化技术:3D并行化(数据、张量、序列并行等)显著提升大规模模型训练与推理效率。
- 线性-二次时间步进调度:推理速度提升至20倍,同时保持生成质量。
性能表现
在性能表现方面,Movie Gen 展示了其在多个多媒体生成任务中的领先地位,尤其是在视频和音频生成方面表现出色,超越了当前多个商用系统。以下是具体的性能表现总结:
1. 文本到视频生成
- 领先的生成质量:Movie Gen在文本到视频生成任务上超越了多个商用系统,包括 Runway Gen3、LumaLabs 和 OpenAI Sora。它能够生成高质量的视频,并在多个关键指标上表现优异。
- 生成视频的长度和帧率:Movie Gen Video模型支持生成最高16秒的视频,帧率达到16帧/秒,并且能够处理多种分辨率和视频时长,最大支持到1080p的高清分辨率。
- 多任务表现:Movie Gen不仅可以根据文本生成视频,还能处理从图像到视频的生成任务,使其在多个场景中具有广泛应用。
2. 个性化视频生成
- 领先的个性化生成能力:Movie Gen通过后续训练,增强了个性化视频生成的功能。该模型能够根据用户输入的图像生成带有个性化特征的视频,并保持生成人物的身份一致性。这种个性化功能在现有的商用系统中并未广泛实现,Movie Gen在这一任务中表现突出。
- 视频一致性:在生成的视频中,Movie Gen能够保持视频中人物和场景的一致性,这点在视频个性化任务中尤其重要。
3. 精确视频编辑
- 精确编辑能力超越现有系统:Movie Gen Edit模型在视频编辑任务上表现优秀,能够根据用户的文本指令精确地编辑视频,例如修改场景中的元素、增加特殊效果等。相比之下,现有的商用系统通常缺乏这种精确的编辑能力。
- 无监督视频编辑:Movie Gen使用了一种创新的方法,通过无监督的方式训练视频编辑模型,这使得它能够在没有大规模监督数据的情况下执行复杂的视频编辑任务。
4. 视频到音频生成
- 高质量音效和背景音乐:Movie Gen Audio模型能够生成48kHz的高质量音频,并且与视频完美同步。相比ElevenLabs和PikaLabs等商用系统,Movie Gen Audio在音效生成、音乐生成和音频扩展任务中表现优异。
- 背景音效生成:该模型不仅能够生成与视频动作匹配的音效,还能够生成与场景相关的环境音效,即使这些声音在视频中是不可见的。
5. 基准测试结果
- 整体性能优于商用系统:在多项基准测试中,Movie Gen的表现均超过了当前的商用生成系统。特别是在文本到视频生成、个性化视频生成、精确视频编辑和音频生成方面,Movie Gen显著领先于竞争对手。
- 特定任务的性能表现:
- 视频生成质量:Movie Gen在生成的整体视频质量上超越了包括Runway Gen3、LumaLabs等系统。
- 视频个性化和一致性:在视频个性化生成和视频一致性任务上,Movie Gen也明显超越了其他模型。
- 音频生成质量:Movie Gen Audio在生成音效和音乐的音质上,击败了PikaLabs和ElevenLabs等商用音频生成模型。
6. 视频生成速度
- 推理效率提升:Movie Gen使用了线性-二次时间步进调度策略,使得推理速度大幅提升。在保持生成质量的前提下,Movie Gen能够将推理步骤从传统的250步减少到仅50步,带来了高达20倍的推理速度提升。
- 多任务支持:Movie Gen能够在单个模型框架内高效处理多个生成任务,如文本到视频、视频到音频等,这使得它在实际应用中具备更强的灵活性和实用性。
7. 人类评价结果
- 人类评估中的高得分:Movie Gen通过人类评估测试,涵盖了多个维度的评估指标,包括文本一致性、视觉质量、运动自然性、帧间一致性、现实感和美学。这些维度的综合评分表明,Movie Gen在生成的视频中具有较高的视觉真实感、运动流畅性和美学吸引力。
- 对不常见场景的良好泛化能力:Movie Gen在生成不常见场景和主题时,也展现出了较强的泛化能力,例如生成虚构角色或非自然动作的视频,这表明该模型能够应对复杂的生成任务。
官网:
https://ai.meta.com/research/movie-gen/
技术报告:
https://ai.meta.com/static-resource/movie-gen-research-paper

